担当:出口光一郎,鏡 慎吾,嵯峨 智 (東京大学)
本研究では,IMAP-VISIONのビデオインターフェイス部において 30Hz でサン
プリングされた, ![]() 画素の 8bit 濃淡動画像から,実時間(ビ
デオレート)でオプティカルフローを計算するソフトウェアを開発し,それを
用いた注視制御システムによってオプティカルフローから物体の3次元形状を
復元するシステムを実現した.以下では,IMAP-VISIONによる実時間オプティ
カルフロー計算アルゴリズムの概要を述べる.システム全体については,本報
告書
画素の 8bit 濃淡動画像から,実時間(ビ
デオレート)でオプティカルフローを計算するソフトウェアを開発し,それを
用いた注視制御システムによってオプティカルフローから物体の3次元形状を
復元するシステムを実現した.以下では,IMAP-VISIONによる実時間オプティ
カルフロー計算アルゴリズムの概要を述べる.システム全体については,本報
告書 を参照していただきたい.
を参照していただきたい.
オプティカルフローを計算する方法の1つとしてブロックマッチング法があり, ある 1 点における移動ベクトルを求めるには,
これを並列処理で行う場合,アルゴリズムとしては,次の2つのものがある.
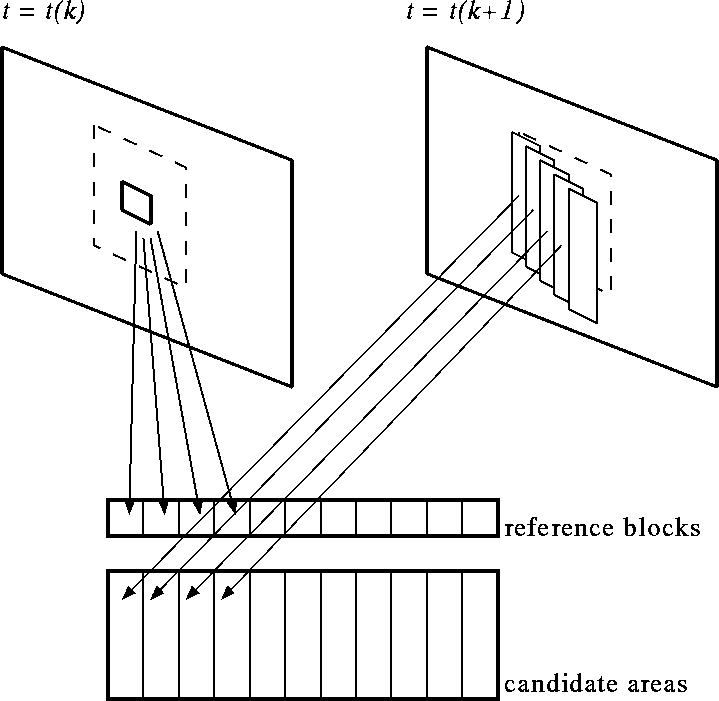
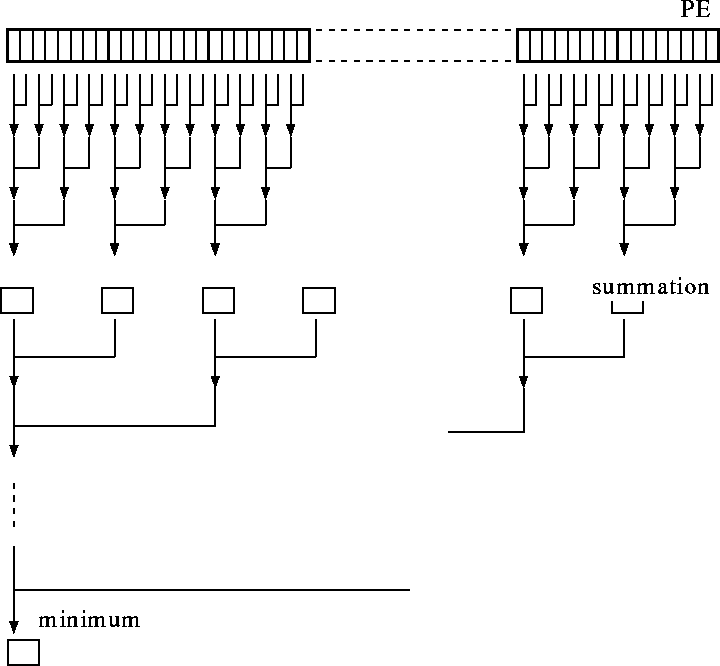
実際にマッチング計算を行うには,図9 のように 参照ブロックと,サーチ領域内の画像をプロセッサアレイ上のメモリに配置す る.具体的には,まず参照ブロック(横幅rピクセル)の第0列〜第r-1 列をPE0〜r-1(PE 番号は左から順に 0 から数えるとする)にそれぞれ格納 する.次に同じ参照ブロックの第0列〜第r-1列をPEr〜2r-1にそれぞ れ格納する…という操作をサーチ領域の横幅回繰り返す.一方,サーチ領域は, まず左端から r ピクセル分だけ切り出しPE0に格納し,次に 1 ピクセル だけ横にずらしてやはり r ピクセル切り出しPE1に格納,…というように, それぞれ隣と 1 ピクセルだけずれたものが順番に並べられる(図 10).
一度このように配置してしまえば,対応する画素ごとの明度差,およびその縦
方向の総和はすべて,各 PE 内で並列に計算できる.その後, ![]() であるPEが,自分を含め右隣 r 個のPEが計算
した明度差の縦部分和を足しあわせるで各ブロックにおける明度差の総和を計
算することができる.そして,これらの総和の中から最小値を選ぶことで,移
動ベクトルが決定できる.横方向の集計(明度差の総和および総和中の最小値
計算)は,図11 のようにピラミッド状に計算するこ
とで効率良く行うことができる.
であるPEが,自分を含め右隣 r 個のPEが計算
した明度差の縦部分和を足しあわせるで各ブロックにおける明度差の総和を計
算することができる.そして,これらの総和の中から最小値を選ぶことで,移
動ベクトルが決定できる.横方向の集計(明度差の総和および総和中の最小値
計算)は,図11 のようにピラミッド状に計算するこ
とで効率良く行うことができる.
r = 8 である場合には,サーチ領域を横幅 32 ピクセルとすることで,256 個の PE をフルに活用することができる.サーチ領域を横幅 16 ピクセルとす ると PE の半分は遊んでしまうが,この場合はサーチ領域を上下に分割して, 余った半分の PE に割り当ててやればよい.
しかし,サーチ領域を横幅 8 ピクセルまで小さくして,縦方向に 4 分割する と,再配置にかかるオーバヘッドが相対的に大きくなるため,あまり効果的で はない. このような場合にはむしろ,移動ベクトルの計算点を 4 ヶ所並行し て計算する方が効率がよい.
上記のアルゴリズムに基づいてIMAP-VISION用ソフトウェアを作成し,ビデオ
レート(33ms)内で計算を完了することが実証できた.本研究で開発した実時間
オプティカルフロー計算プログラムは,本プロジェクトの共通ライブラリとし
て公開されている(詳細は,本報告書を参照).