All technological issues discussed so far are of observation stations, a realization of a vacuous AVA. Here we describe our approach to the cooperation among mobile robots with vision, a realization of embodied AVA.
Our major interest is in how robots can learn cooperative behaviors through visual learning. We developed a mobile robot testbed shown in Fig. 21:
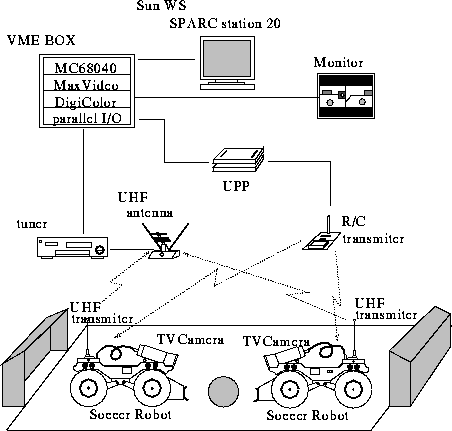
Figure 21: Testbed for cooperative soccer robots.
In the case of embodied AVAs, the visual scene of one AVA includes the other AVAs moving around independently, so that its geometric and temporal structures become very complicated. To simplify image processing, objects in the scene are color coded; their segmentation can be done based on their colors.
Based on the linear dynamic system model discussed in Section 3.4, we proposed a vision-based reinforcement learning method for mobile robots to acquire cooperative behaviors. The task of robots is to play a soccer game, where a robot searches for a rolling red ball and pushes it toward a blue goal avoiding yellow opponent robots. (See [15] for technical details.)
Experimental results demonstrated that a shooter robot can shoot a rolling ball passed by another passer robot successfully. As discussed in Section 3.4, however, the model as well as the implemented robot system should be improved to realize more complex cooperative and competitive behaviors.
