担当:松山 隆司(京都大学)
本プロジェクトでは,上記のような個別的応用システムの構築を目指すのでは なく,それらの共通プラットフォームとなる分散協調型実時間視覚情報処理機 構を実現するための基盤技術,特に,ネットワーク接続されたマルチカメラに よる多角的映像撮影・処理手法,分散協調視覚システム内部およびシステムと 外的世界との協調的相互作用・コミュニケーション方式を重点的に研究するこ とを目的としている.
本研究では,プロジェクトが進める技術的,工学的研究の基礎となる,分散協 調視覚の理論モデルの構築を目指して研究を行い,以下の成果を得た.
本年度は,まず,従来の人工知能研究で用いられてきた 知能 = 知識 + 推論
という図式に代り,外界・他者とのインタラクションに基づく知能のモ
デル化,あるいは知覚,行動 ,コミュニケーション機能の統合による知能の創発という考え方,
すなわち
知能 = 知覚 + 行動 + コミュニケーション
,コミュニケーション機能の統合による知能の創発という考え方,
すなわち
知能 = 知覚 + 行動 + コミュニケーション
という図式を知能の基本モデルとして提案した.これに基づき,分散協調視覚 の基本モデルは, 分散協調視覚 = 視覚 + 行動 + コミュニケーション
と定義される.
この基本モデルを具体化するために,本年度は,視覚,行動,コミュニケーショ ン機能を備えた自律システム(能動視覚エージェント,Active Vision Agent,略してAVA)の機能モデルを設計し,視覚,行動,コミュニケーション 機能の間の相互関係について検討した(図2, 3).
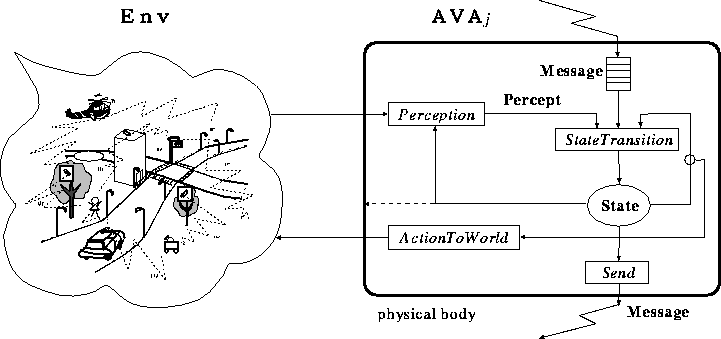
Figure 2: 身体を持つ能動視覚エージェントの機能モデル
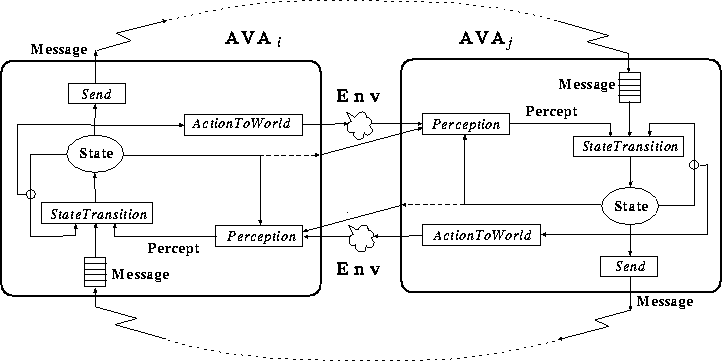
Figure 3: 身体を持つ能動視覚エージェント間のコミュニケーション・チャネル
この機能モデルに基づいた考察により,以下のことが明らかになった.
さらに本研究では,図2, 3のような,エージェントの内部状態を中心とした モデルと,ロボット制御などに使われる状態方程式によるシステムの動作記述 とを比較し,以下の知見を得た.
以上の考察から,分散協調視覚という,ダイナミックなインタラクションに基
づく知能システムのモデルを構築するには,情報科学における状態遷移モデル
とシステム理論における状態方程式を共に包含した新たな枠組みが必要である
ことが分かり,それを具体的モデルとして設計することが次年度以降の研究目
標となる.(詳細は,本報告書 章を参照)
章を参照)
